
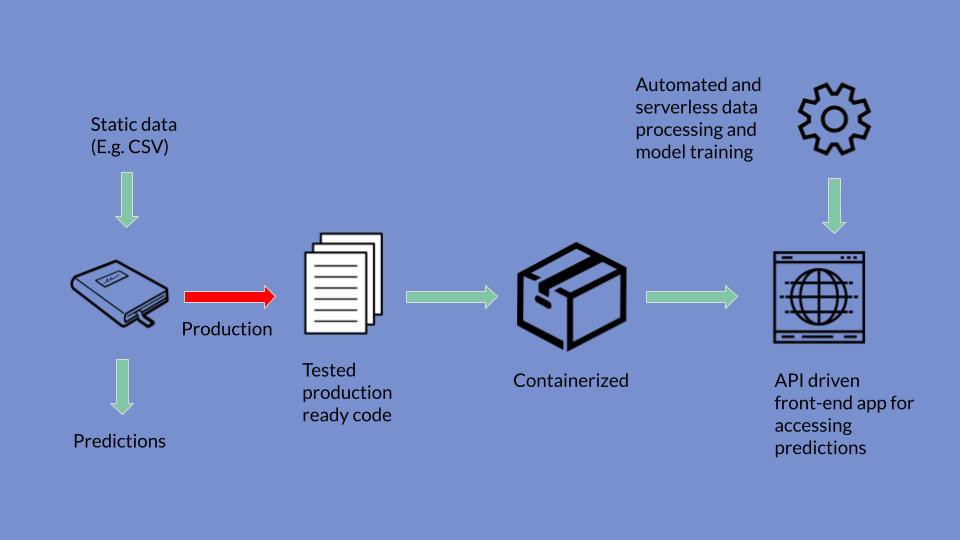
Machine learning (ML) deployment involves putting a working ML model into an environment where it can do the work of the design. The model deployment and monitoring process require extensive planning, documentation, and oversight, as well as a variety of different tools.
But, how to deploy machine learning models?
Table of Contents
What is Model Deployment?
Machine learning model deployment is the process of placing a finished machine learning model into a live environment where it can be used for its intended purpose. Models can be deployed in a wide range of environments, and they are typically integrated with applications through APIs so that end users can access them.
Although deployment is the third phase of the data science life cycle (management, development, deployment, and monitoring), every aspect of model creation is performed with deployment in mind.
Models are typically developed in an environment with carefully prepared data sets, where they are trained and tested. Most models created during development fail to achieve the desired goals. Few models pass the tests and those that do represent a significant investment of resources. Therefore, moving the model into a dynamic environment requires a lot of planning and preparation for the project to succeed.
Why is Model Deployment Important?
In order to start making actual decisions with the model, you need to deploy it effectively into production. If you can’t reliably derive practical insights from the model, its impact is severely limited.
Model deployment is one of the most difficult processes to extract value from machine learning. It requires coordination between data scientists, It teams, software developers, and business professionals to ensure that models work reliably in an organization’s production environment. This is a major challenge because there are often differences between the programming languages used to write machine learning models and languages that production systems can understand, and recoding models can add weeks or months to a project.
To get the most value from machine learning models, they must be deployed seamlessly into production so that enterprises can start using them to make practical decisions.
How To Deploy a Machine Learning Model Into Production
1. Prepare to Deploy the ML model
Models need to be trained before they can be deployed. This involves selecting an algorithm, setting its parameters, and training it on prepared, cleaned data. All of this work is done in a training environment, which is usually a platform specifically designed for research, with the tools and resources needed for experiments. When the model is deployed, it is moved to a production environment where resources can be optimized and controlled for safe and efficient performance.
While completing this development effort, the deployment team can analyze the deployment environment to determine what type of application will access the model once it is complete, what resources (including GPU/CPU resources and memory) it will need, and how to provide data to it.
2. Validate the ML Model
Once the model has been trained and its results are considered successful, it needs to be validated to ensure that its one-time success is not an anomaly. Validation involves testing the model on a new data set and comparing the results with its initial training. In most cases, several different models have been trained, but only a few have been successfully validated. In proven models, only the most successful models are usually deployed.
Validation also includes reviewing training documents to ensure that the method meets organizational requirements and that the data used meets end-user requirements. This validation is typically for regulatory compliance or organizational governance requirements, which may, for example, dictate what data can be used and how it must be processed, stored, and recorded.
3. Deploy THE ML Model
The process of actually deploying the model requires several different steps or operations, some of which will be performed simultaneously.
- First, the model needs to be moved to its deployed environment, where it can access the hardware resources it needs and the data sources from which it can extract data.
- Second, the model needs to be integrated into the process. This could include, for example, using the API to access from the end user’s laptop, or integrating it into the software the end-user is currently using.
- Third, people who will use the model need to be trained on how to activate the model, access its data, and interpret its output.
4. Monitor ML Model
Once the model is successfully deployed, the monitoring phase of the data science life cycle begins.
Model monitoring can ensure that the model works properly and its prediction is valid. Of course, it’s not just the model that needs to be monitored, especially during early runs. Deployment teams need to ensure that support software and resources are running as required and that end users are adequately trained. Many problems can occur after deployment: resources may be insufficient, data feeds may not be properly connected, or users may not be using their applications correctly.
Once your team has determined that the model and its supporting resources are up and running, monitoring still needs to continue, but most of the monitoring can be automated until something goes wrong.
The best way to monitor a model is to periodically evaluate its performance in a deployed environment. This should be an automated process, using tools that track metrics and automatically alert you when their accuracy, precision, or F score changes.
Each deployed model is likely to degrade over time due to the following issues:
Differences in deployment data. Often, the data provided to the model in deployment is not cleaned up in the same way as the training and test data, resulting in changes to the model deployment.
Changes in data integrity. Over weeks, months, or years, changes to the data entered into the model can adversely affect model performance, such as changes to formatting, renamed fields, or new categories.
Data drift. Changes in demographics, market changes and other aspects may drift over time, making training data less relevant to the current situation, thus reducing the accuracy of model results.
Concept drift. End users’ expectations of correct predictions may change over time, reducing the relevance of model predictions.
Using the enterprise Data science platform, you can use a variety of monitoring tools to automatically monitor each of these issues and notify your data science team immediately when a difference is detected in the model.
5. Model Deployment and Monitoring
Successfully deploying and monitoring machine learning models requires different skill sets and collaborations between many different people on different teams. It also requires experience and the use of tools to help these teams work together efficiently. Model-driven organizations that successfully deploy models on a weekly basis rely on tools and resources, all within an ML operating platform.
Conclusion
In addition to all of the best practices described above, machine learning models should be designed to be reusable and resilient to change and dramatic events. The best-case scenario is not to have all the recommended approaches in place, but to have specific domains mature and extensible enough that they can be calibrated up and down according to time and business needs.


