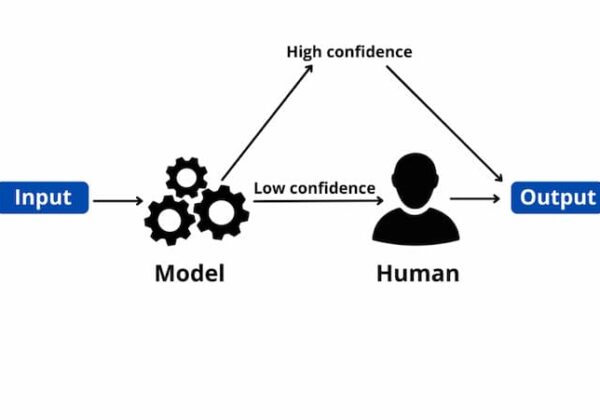
Machine learning (ML) inference involves applying a machine learning model to a dataset and producing an output or “prediction”. The output could be a numerical score, a text string, an image, or any other structured or unstructured data. ML inference is typically deployed by DevOps engineers or data engineers. Sometimes, the data scientists responsible for training the models are required to own the ML inference process. So what is exactly machine learning inference?
Table of Contents
What Is a Machine Learning Inference Server?
A machine learning inference server or engine executes model algorithms and returns inference output. The way an inference server works is that it accepts input data, passes it to a trained ML model, executes the model, and returns the inference output.
The ML inference server requires the ML model creation tool to export the model in a file format that the server can understand. For example, the Apple Core ML inference server can only read models stored in model file format. If you used TensorFlow to create your model, you can use the TensorFlow conversion tool to convert the model to model file format.
You can use the Open Neural Network Interchange Format (ONNX) to improve file format interoperability between various ML inference servers and model training environments. ONNX provides an open format for representing deep learning models, enabling greater model portability between ML inference servers and tools for ONNX-enabled vendors.
What Are the Constraints In Executing ML Inference?
- Cost: The total cost of inference is a major factor in the efficient functioning of AI/ML. Various computing infrastructures for AI and ML in production environments include GPUs and CPUs in data centers or cloud environments. Workloads must optimally utilize hardware infrastructure to ensure cost per inference is kept under control. One way is to run concurrent queries, i.e. batches.
- Delayed budgets: Budgets vary by ML use case. Mission-critical applications often require real-time inference to minimize the available latency budget. Autonomous navigation, critical material handling, and medical equipment often require such low latency. On the other hand, some use cases with complex data analysis have relatively high latency budgets. Business and consumer decisions require suggested insights based on contextual (internal and external) data. You can run these details in optimal batches based on the frequency of inference queries and make them available to decision-makers at any time.
Another key factor is the diversity of the enterprise technology environment. Data scientists from different teams work on different problems. Different ML solution development frameworks like Tensorflow, Pytorch, and Keras are best suited for solving these problems. Once these models are trained and released into production, the various model configurations need to work well together at scale. Production environments are diverse, with multiple inference areas in scope – device, edge, and data center/cloud. Containerization has become a common practice in enterprise production environments. Kubernetes-based deployments have different deployment options. There is widespread adoption of Kubernetes services from AWS, Microsoft Azure, and Google Cloud (leading public cloud providers). There are also virtualization and bare metal hardware deployments.
How Does Machine Learning Inference Work?
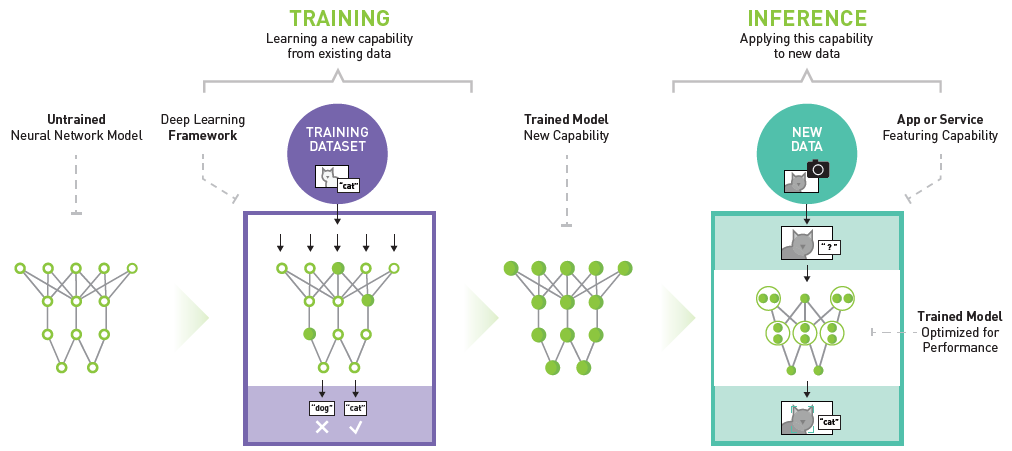
Deploying machine learning inference requires three main components: the data source, the system hosting the ML model, and the data destination.
- data source
Data sources capture real-time data from internal sources managed by the organization, external sources, or application users.
Examples of common data sources for ML applications are log files, transactions stored in a database, or unstructured data in a data lake.
- host system
The host system of the ML model receives data from the data source and feeds it into the ML model. It provides the infrastructure to run ML model code. After the ML model generates outputs (predictions), the host system sends those outputs to the data destination.
Common examples of host systems include API endpoints that accept input via REST APIs, web applications that receive input from human users, or stream processing applications that process large amounts of log data.
- data destination
The data destination is the target of the ML model. It can be any type of data repositories, such as a database, a data lake, or a stream processing system that feeds data to downstream applications.
For example, the data destination may be a web application’s database that stores predictions and allows end users to view and query predictions. In other scenarios, the data destination might be a data lake, where predictions are stored for further analysis by big data tools.
Challenges of Machine Learning Inference
As mentioned earlier, jobs in ML inference can sometimes be wrongly assigned to data scientists. Data scientists may not be able to deploy successfully if only a set of low-level tools for ML inference is provided.
Additionally, DevOps and data engineers are sometimes unable to help with deployment, often due to conflicting priorities or a lack of understanding of what is required for ML inference. In many cases, ML models are written in languages like Python, which is popular among data scientists, but IT teams are more proficient in languages like Java. This means engineers have to translate Python code to Java to run in their infrastructure. Furthermore, the deployment of the ML model requires some additional coding to map the input data to a format acceptable to the ML model, and this extra work increases the burden on engineers when deploying the ML model.
Additionally, the ML lifecycle often requires experimentation and regular updates to ML models. If deploying the ML model in the first place is difficult, then updating the model is almost as difficult. The entire maintenance effort can be difficult as business continuity and security issues need to be addressed.
Another challenge is getting performance appropriate for the workload. REST-based systems that perform ML inference typically have low throughput and high latency. This may work in some environments, but modern deployments dealing with IoT and online transactions face enormous loads that can overwhelm these simple REST-based deployments. The system needed to be able to scale not only to handle growing workloads but also to handle temporary load spikes while maintaining consistent responsiveness.
When adopting a machine learning strategy, technology choice is important to address these challenges. Hazelcast is an example of a software vendor that provides in-memory and streaming technologies that are ideal for deploying ML inference. Open-source version to try out the technology without a principal
What Tools Are Available For ML Inference Serving?
Various open source, commercial, and integrated platform tools are available for inference services. Open source tools include Tensorflow Serving, TorchServe, Triton, Cortex, and multi-server models. Others include KFServing (part of Kubeflow), ForestFlow, DeepDetect, and BentoML. Most of these support all leading AI/ML development frameworks (TensorFlow, Pytorch, Keras, and Caffe) and integrate seamlessly with leading DevOps and MLOps tool stacks.
Einfo Chips is an Arrow company with strong expertise in ML solution development, from concept to operation. We help clients in the smart building, fleet management, medical device, retail, and home automation industries build and launch smart, connected products at scale using computer vision and natural language processing technologies.
Conclusion
In conclusion, a machine learning model is software code that implements a mathematical algorithm. The machine learning inference process deploys this code into a production environment, where it can generate predictions for input provided by real end users.