

Do you want to know the distinction between federated and distributed learning? To find out, read this article.
Distributed machine learning refers to multinode machine learning algorithms and systems that are designed to improve performance, increase accuracy, and scale to larger input data sizes.
It lowers machine errors and helps people use vast amounts of data to conduct accurate analyses and make decisions.
Keep reading and learn the differences between distributed machine learning and federated machine learning.
Distributed Machine Learning
Using independent training on various nodes, the distributed machine learning algorithm creates training models. The training on enormous amounts of data is accelerated by using a distributed training system. Scalability and online re-training are necessary because training time grows exponentially when using big data.
Let’s say, for instance, that we want to create a recommendation model and that we want to retrain the model based on daily user interaction. Millions of users and hundreds of clicks per user are possible levels of user interaction. In this case, the daily training of the recommendation model requires the use of a vast amount of data. Here, it is possible to create distributed learning systems and parallelize training to save time.
Read Next: Anomaly Detection In Machine Learning
Federated Machine Learning
The conventional AI algorithms call for centralizing data on a single computer or server. This method’s drawback is that all of the information is sent back to the central server for processing before being sent back to the devices. The entire procedure restricts the speed at which a model can learn.
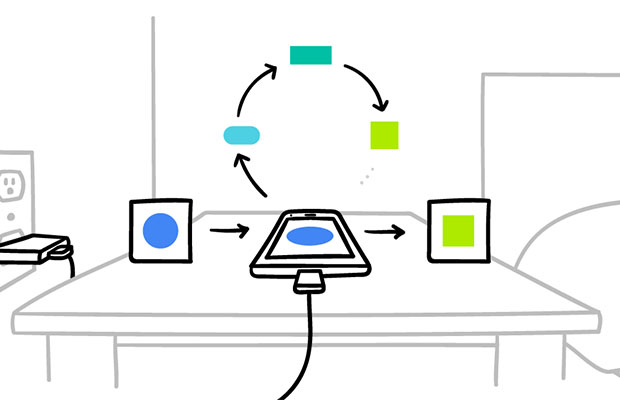
A centralized server-first approach is federated learning. It uses a distributed ML approach where a model is jointly trained by a number of users. The 2017 Google AI blog was the first to discuss the idea of federated learning. The raw data is distributed in this case instead of being transferred to a single server or data center. It picks out a few nodes and sends the initialized version, which contains model parameters for an ML model, to each node. Now, each node runs the model, trains the model on its own local data, and has a local copy of the model.
Federated Learning utilizes methods from numerous fields of study, including distributed systems, machine learning, and privacy. FL works best when on-device data is more pertinent than data stored on servers.
Federated learning offers cutting-edge ML to edge devices without by default centralized data and privacy. As a result, it manages the unbalanced, non-Independent, and Identically Distributed (IID) data of the features in mobile devices. Smartphones generate a large amount of data that can be used locally at the edge with on-device inference. This enables quick working with battery savings and better data privacy because the server does not need to be informed of every interaction with the locally generated data.
By using an on-device cache of local interactions, Google’s Gboard, for instance, aims to be the most privacy-forward keyboard. For federated learning and computation, this data is used.
Federated ML Vs Distributed ML
Federated Learning and Distributed Learning differ in three significant ways:
- FL prohibits the transmission of direct raw data. Such a limitation does not apply to DL.
- FL uses distributed computing resources across a number of locations or businesses. DL uses a solitary server or cluster in a solitary region that is a part of a solitary company.
- FL typically makes use of encryption or other defensive strategies to guarantee data security or privacy. FL assures that the raw data’s security and confidentiality will be maintained. In DL, safety is not as heavily emphasized.
- Federated learning makes use of methods from a variety of fields of study, including distributed systems, machine learning, and privacy. One could argue that federated learning is an improvement over distributed learning.
You May Also Like:


