
Using stacking, you can combine different regression or classification models. There are many ways to ensemble models, the widely known models are Bagging or Boosting.
Stacking machine learning enables us to train multiple models to solve similar problems, and based on their combined output, it builds a new model with improved performance.
Discover more about stacking by reading on.
Table of Contents
What is Stacking in Machine Learning?
Stacking (sometimes called Stacked Generalization) is a different paradigm. The point of stacking is to explore a space of different models for the same problem. The idea is that you can approach a learning problem with various types of models, each of which is capable of learning a portion of the problem but not the entire problem space.
Therefore, you can create a variety of learners and use them to create intermediate predictions, one for each learned model. Then you incorporate a new model that gains knowledge of the same target from intermediate predictions.
The last model is referred to as being stacked on top of the others, hence the name. As a result, your performance may be improved overall, and you frequently produce a model that is superior to each individual intermediate model.
However, keep in mind that, as with all machine learning techniques, it does not provide any guarantees.
Also Read:
How Stacking Works?

- We divided the training data into K-folds in the same manner as K-fold cross-validation.
- On the K-1 parts, a base model is fitted, and predictions are made for the Kth part.
- We carry out for each section of the practice data.
- The performance of the base model on the test set is then calculated by fitting it to the entire train data set.
- For additional base models, the previous three steps are repeated.
- For the second level model, predictions from the train set serve as features.
- An assumption is made about the test set using a second level model.
Architecture of Stacking
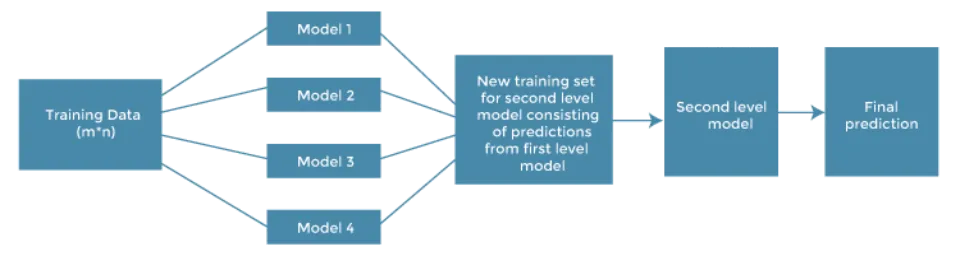
A meta-model that combines the predictions of the base models makes up the stacking model’s architecture, which consists of two or more base/learner’s models. These foundational models are level 0 models, and the meta-model is a level 1 model. So, the Stacking ensemble method includes original (training) data, primary level models, primary level prediction, secondary level model, and final prediction. The illustration below can serve as a representation of the fundamental stacking architecture.
- Original data: This information, which has been divided into n-folds, can be used as training or test data.
- Base models: As level-0 models, these models are also known as. These models generate compiled predictions (level-0) using training data.
- Level-0 Predictions: Each base model is triggered on some training data and provides different predictions, which are known as level-0 predictions.
- Meta Model: One meta-model makes up the stacking model’s architecture, which aids in combining the base models’ predictions in the best way possible. The meta-model is also known as the level-1 model.
- Level-1 Prediction: The meta-model is trained on various predictions made by various base models, i.e., data not used to train the base models are fed to the meta-model, predictions are made, and these predictions, along with the expected outputs, provide the input and output pairs of the training dataset used to fit the meta-model.
How to Implement Stacking Models:
Implementing stacking models in machine learning involves a few crucial steps. These are as follows:
- Split training data sets into n-folds using the RepeatedStratifiedKFold as this is the most common approach to preparing training datasets for meta-models.
- Now that the first fold, which is n-1, has been fitted to the base model, it will be able to predict the nth folds.
- The x1_train list is expanded to include the prediction from the previous step.
- Repeat steps 2 & 3 for remaining n-1folds, so it will give x1_train array of size n,
- As soon as all n parts have been trained, the model will be able to predict the results of the sample data.
- To the y1_test list, add this prediction.
- By using Models 2 and 3 for training, respectively, we can find x2_train, y2_test, x3_train, and y3_test to obtain Level 2 predictions.
- Now, train the Meta model using level 1 predictions, which will be the model’s features.
- Finally, a prediction on test data in the stacking model can now be made using meta learners.
Summary of Stacking Machine Learning
Stacking is an ensemble method that enables the model to learn how to use combine predictions given by learner models with meta-models and prepare a final model with accurate prediction.
The main advantage of using a stacking ensemble is that it can protect the ability of a variety of effective models to solve classification and regression issues. It also aids in developing a better model with predictions that are superior to those of all individual models.
We have learned about different ensemble techniques and their definitions in this topic, as well as about the stacking ensemble method, the structure of stacking models, and the steps involved in implementing stacking models in machine learning.
You May Also Like:
- GPU Machine Learning
- Anomaly Detection In Machine Learning
- What Are Model Parameters In Machine Learning?
FAQs
What is Stacking Vs Bagging in Machine Learning?
In general, boosting and stacking will try to create strong models that are less biased than their components (even though variance can also be reduced), whereas bagging will primarily focus on getting an ensemble model with less variance than its components.
What Are Advantages of Stacking Machine Learning?
The advantage of stacking is that it can use a variety of powerful models to perform classification or regression tasks and produce predictions that perform better than any one model in the ensemble.


