Many different parameters affect the model’s performance. A model is deemed to be successful if it achieves high accuracy in test or production data and can generalize successfully to unidentified data. What are model parameters in machine learning?
Model parameters, or weight and bias in the case of deep learning, are characteristics of the training data that will be learned during the learning process.
The machine learning model parameters determine how to input data is transformed into the desired output, whereas the hyperparameters control the model’s shape.
For more information on model parameters and the distinction between a parameter and a hyperparameter, keep reading if you’re interested.
Table of Contents
What Are Model Parameters?
Model parameters are configuration variables that are internal to the model and whose values can be inferred from data.
- In order for the model to make predictions, they are necessary.
- The model’s proficiency with your problem is defined by the values.
- They are calculated or figured out using data.
- They are frequently not manually set by the practitioner.
- The learned model frequently includes them as saved data.
Machine learning algorithms depend on parameters. They are the portion of the model that is educated using historical training data.
We can think of the model as the hypothesis in the literature on classical machine learning, and the parameters as how the hypothesis is tailored to a particular set of data.
Utilizing an optimization algorithm, which is a kind of effective search through potential parameter values, is a common method for estimating model parameters.
- Statistics: A distribution, such as a Gaussian distribution, can be assumed in statistics for a variable. Two parameters of the Gaussian distribution are the mean (mu) and the standard deviation (sigma). This is true for machine learning, where these parameters may be estimated from data and used as a component of a predictive model.
- Programming: A parameter may be passed to a function in programming. A parameter in this context is a function argument that can take on a variety of values. In machine learning, the particular model you’re using is the function and needs inputs to make a forecast based on fresh data.
Whether a model has a fixed or variable number of parameters determines whether it may be referred to as “parametric” or “nonparametric“.
Examples of model parameters are:
- an artificial neural network’s weights.
- the supporting vectors in a supporting vector machine.
- the coefficients in logistic or linear regression.
Good And Right-Fit Models
Good models are defined as those who are neither overfitting nor underfitting. Right-fit models are those with the least minimal bias and variance errors.
Accuracy in both training and testing can be estimated concurrently. The performance of the model cannot be assessed by a single test. K-fold cross-validation and bootstrapping sampling are used to simulate test sets because there aren’t enough of them.
What then are modeling errors? Modeling errors are defined as errors that reduce a model’s ability to predict. The three types of modeling errors that are most frequently made are as follows:
- Variance error is defined as the variance noticed in the model’s behavior. Different samples will yield different results from machine learning model parameters. Due to the degree of freedom for the data points, if the features or attributes in a model are increased, the variance will also increase.
- Bias Error: Any stage of the modeling process, beginning with the data collection phase, is susceptible to this kind of error. It may occur while analyzing the data to determine the features. Additionally, after classifying the information into three groups, training, validation, and testing. Class size bias occurs when algorithms favor the class with the most members over the other classes.
- Random Errors: These are mistakes that happen for unknown reasons.
About Validation Of The Model
A model’s performance is evaluated through the validation process. It is not a given that if your model performs well during the training stage, it will perform well during the production stage. Always divide your data into two segments, one for training data and the other for testing data, if you need to validate your model.
It is often found that there is not enough data to divide the population into train and test groups. Therefore, it may not be the best method to predict the error on production data to check the model’s error on test data. The model error in production can be assessed using a number of different strategies in cases where there aren’t much big data.
How frequently the examination is run will be decided by the user. A value known as “k,” which is an integer value, must be selected by the user. The steps in the sequence are repeated as many times as the value of ‘k.’ You must first use random functions to divide the original data into various folds before you can perform cross-validation.
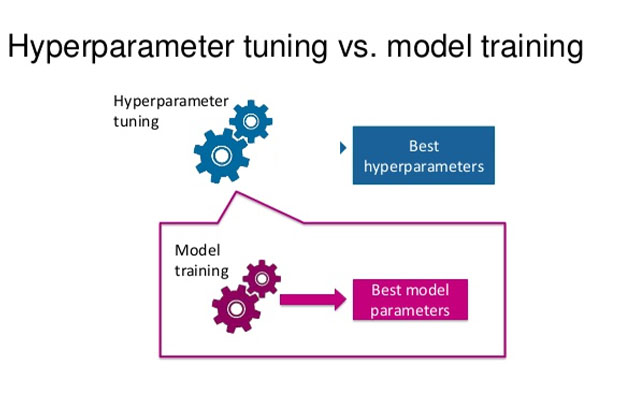
What Is Model Hyperparameter?
The definition of a model hyperparameter is a configuration that is external to the model and whose value cannot be inferred from data.
- They are frequently used in procedures to assist in model parameter estimation.
- A practitioner will frequently specify them.
- Heuristics are often useful in setting them.
- They are frequently adjusted for a specific predictive modeling issue.
The ideal setting for a model hyperparameter for a specific problem is unknown to us. We can rely on generalizations, copy values from other problems, or use trial and error to find the best value.
When a machine learning algorithm is tuned for a particular problem, as when using a grid search or a random search, you are tuning the hyperparameters of the model or looking for the model’s parameters that produce the most accurate predictions.
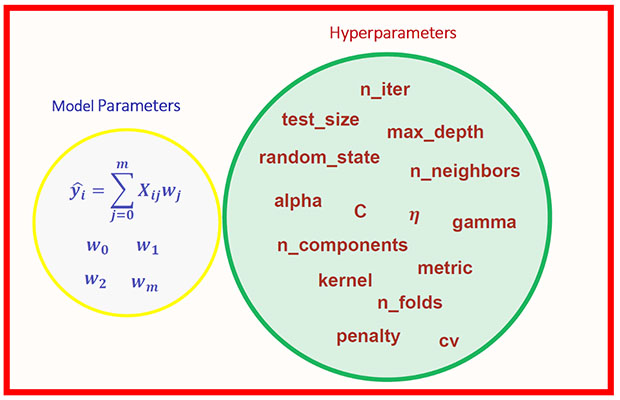
Difference Between Model Parameters And Hyperparameters
PARAMETERS
- They are required for making predictions
- They are estimated by optimization algorithms(Gradient Descent, Adam, Adagrad)
- They are not set manually
- The final parameters found after training will decide how the model will perform on unseen data
HYPERPARAMETER
- They are required for estimating the model parameters
- They are estimated by hyperparameter tuning
- They are set manually
- The selection of hyperparameters affects how effective the training is. In gradient descent, the learning rate decides how efficient and accurate the optimization process is in estimating the parameters
Summary
You learned the precise definitions of model parameters and model hyperparameters in this post, as well as their distinctions.
Model hyperparameters are manually set and used in processes to aid in the automatic estimation of model parameters from data.
Other Posts You Might Like: Machine Learning Model Training